使用AI变声器
安装RVC
GitHub:RVC-Project/Retrieval-based-Voice-Conversion-WebUI: Easily train a good VC model with voice data <= 10 mins! (github.com)
本教程所使用环境:Windows11,CPU:x86,GPU:Tesla P100,Anaconda,Python 3.10.14(项目指明需要>=3.9、<3.11)。
克隆项目并进入目录:
git clone https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI.git
cd Retrieval-based-Voice-Conversion-WebUI
## 创建Python环境后,安装pip包
pip install requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
## 卸载cpu版torch,并安装cuda版
pip uninstall torch torchvision torchaudio -y
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118运行变声器
可以看到,go-realtime-gui.bat,内写了打开方式:runtime\python.exe gui_v1.py --nocheck
但是我们用的是Conda生成的Python环境,改为:.conda\python.exe gui_v1.py
双击bat即可运行。
看到以下状态就是成功运行起来了。
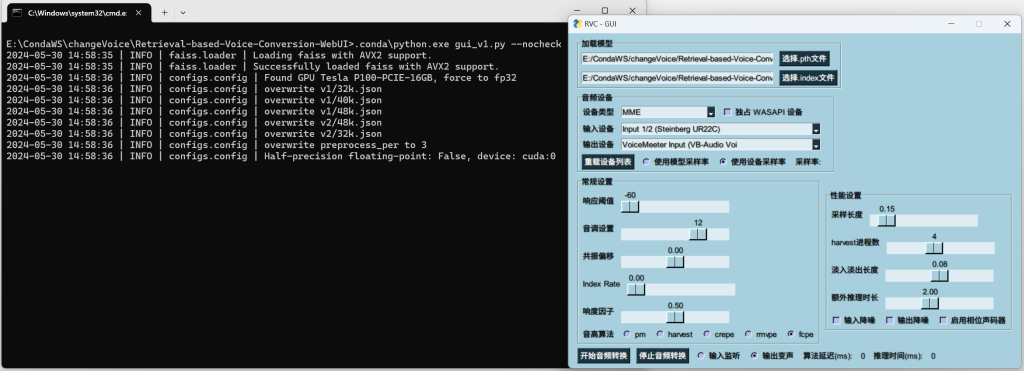
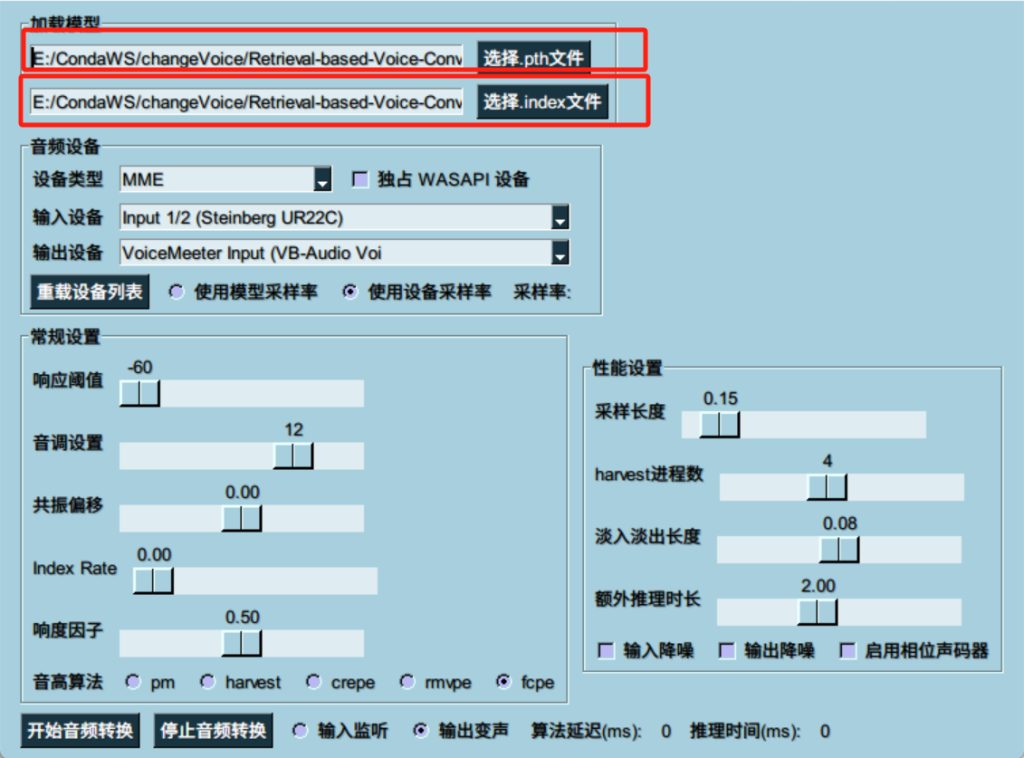
选择模型和索引文件,调整输入输出设备即可。
输入设备为麦克风,输出设备这里设置的是虚拟声卡,大家可以去官网下载:VB-Audio VoiceMeeter。
训练模型
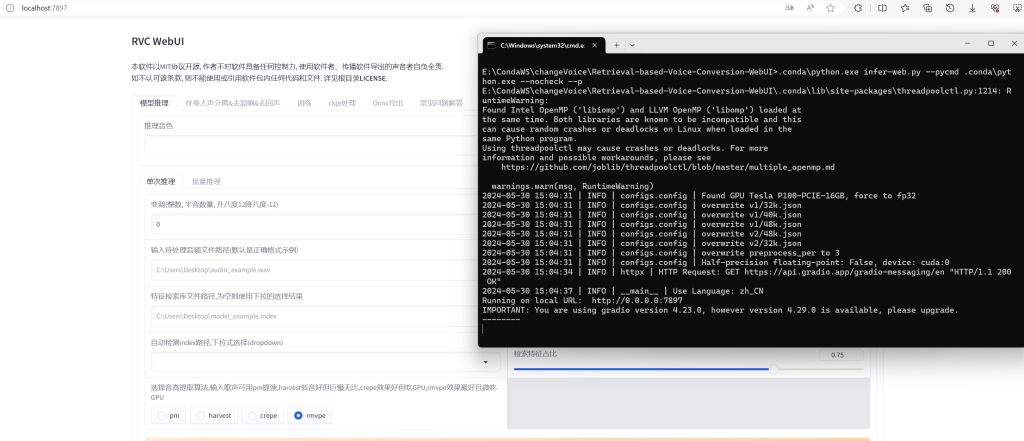
训练模型用的是网页版,可以看到go-web.bat文件,里面写着打开方式为:runtime\python.exe infer-web.py --pycmd runtime\python.exe --nocheck --port 7897
同样将其改为:.conda\python.exe infer-web.py --pycmd .conda\python.exe --nocheck --port 7897
双击运行,没问题会自动打开http://localhost:7897,如下图所示。
按照以下修改后点击一键训练即可:
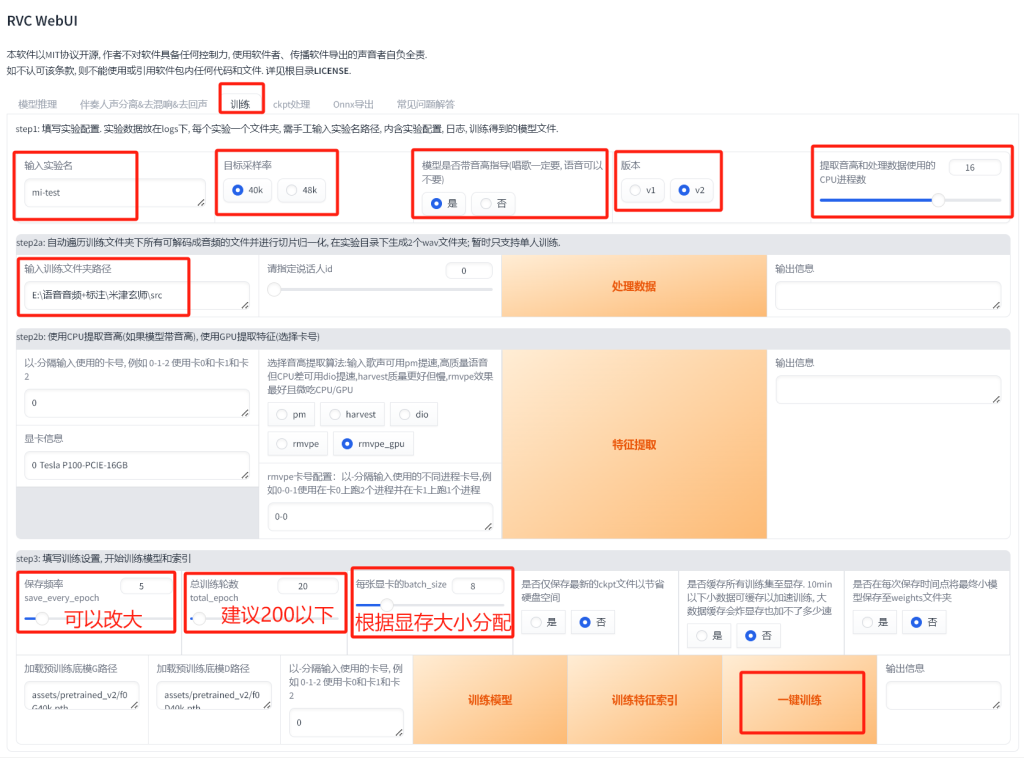
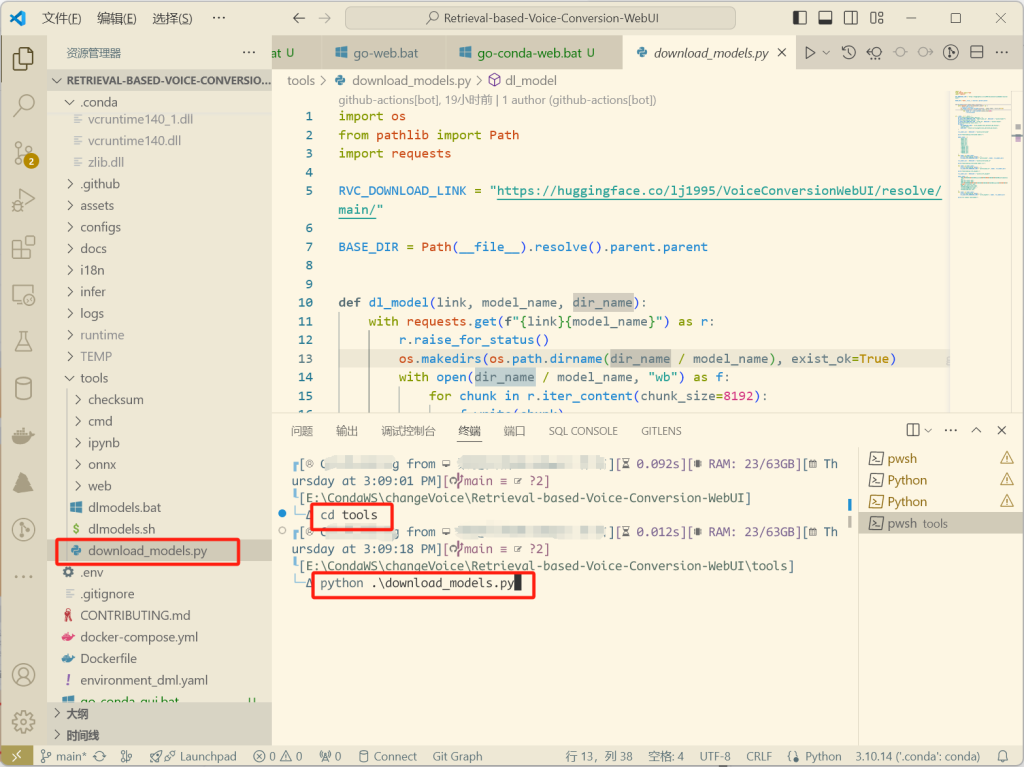
如果遇到没有下载模型的提示,则进入tools文件夹运行download_models.py即可。
最后将\assets\weights下得到的.pth格式的模型和\logs\[实验名]下的added_***.index音高索引填入RVC中即可通过该模型输出。