本文最后更新于 278 天前,其中的信息可能已经有所发展或是发生改变。
最近浏览bilibili看到这个开源的TTS,刚好可以用来弥补FastGPT没有免费TTS的问题
教程N卡环境:Tesla P100-16G;Python环境:conda/python3.10.14
下载源码
# 克隆ChatTTS本体
git clone --depth 1 https://github.com/2noise/ChatTTS.git
# 下载所需的pip包
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
# 卸载CPU的torch
pip uninstall torch torchvision torchaudio -y
# 下载CUDA的torch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 下载缺少的gradio、Cython包
pip install gradio Cython -i https://pypi.tuna.tsinghua.edu.cn/simple
# 还有WeTextProcessing
conda install -c conda-forge pynini=2.1.5 && pip install WeTextProcessing -i https://pypi.tuna.tsinghua.edu.cn/simple
# 克隆ChatTTS模型 需要下载git lfs,自行搜索,我这边将其放在ChatTTS\model\下
cd .\ChatTTS\model\
git clone https://www.modelscope.cn/pzc163/chatTTS.git运行webui
# 因为模型放在.\ChatTTS\model\chatTTS\下,因此:
python .\webui.py --local_path .\ChatTTS\model\chatTTS\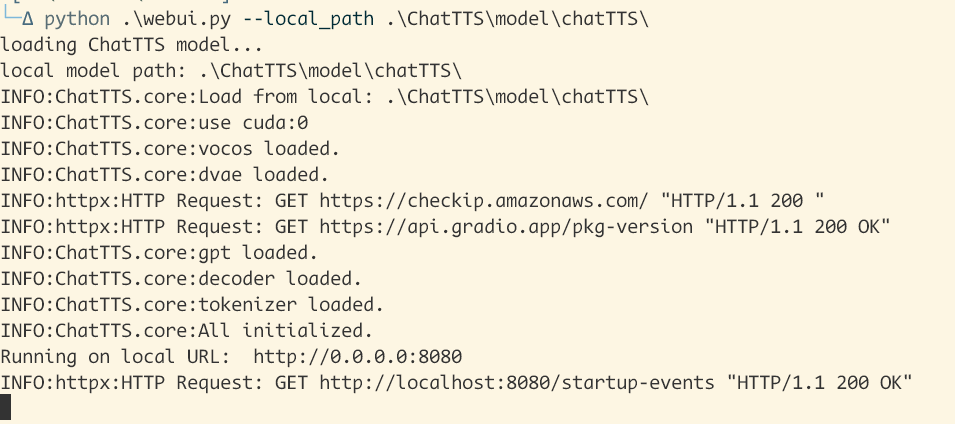
默认会打开http://localhost:8080
由于在运行时出现该情况:
RuntimeError: Found Tesla P100-PCIE-16GB which is too old to be supported by the triton GPU compiler, which is used as the backend. Triton only supports devices of CUDA Capability >= 7.0, but your device is of CUDA capability 6.0
RuntimeError:发现Tesla P100-PCIE-16GB太旧,无法由用作后端的triton GPU编译器支持。Triton仅支持CUDA功能>=7.0的设备,但您的设备的CUDA功能为6.0是因为显卡太旧了,不支持最新版的编译器,需要添加两行代码在头部后再次运行:
import torch._dynamo
torch._dynamo.config.suppress_errors = True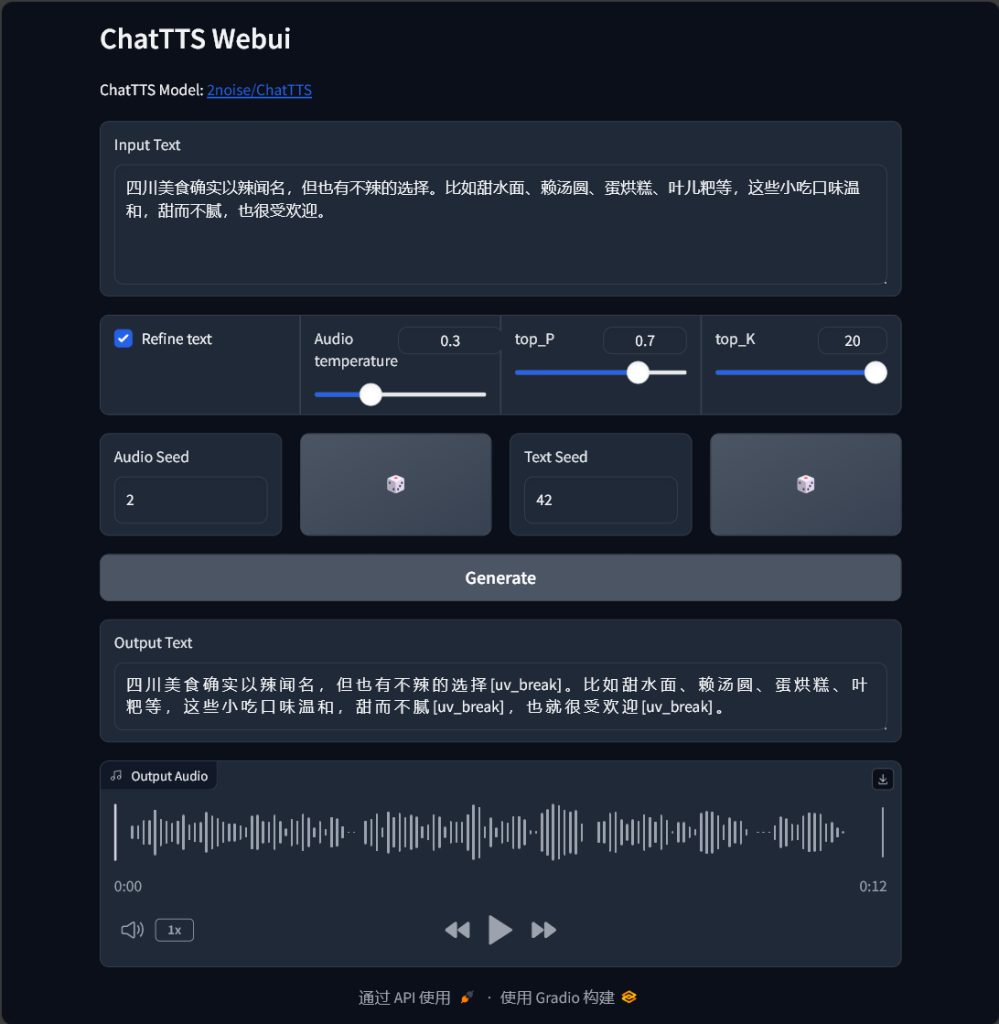
新建openai接口
根据openai的tts接口文档API Reference – OpenAI API可以看到:
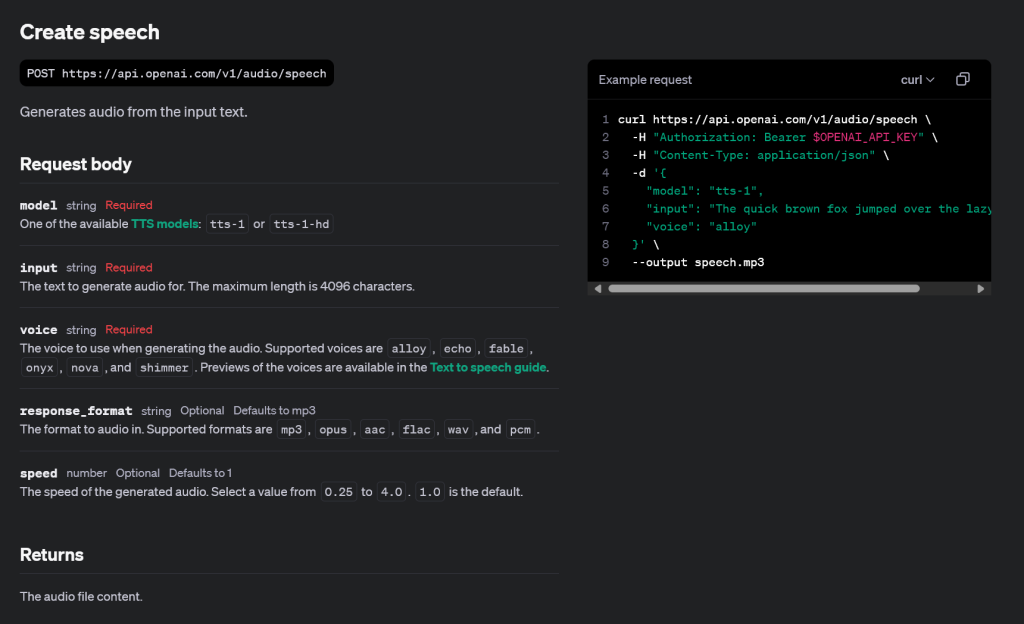
因此我们可以用python的flask框架创建一个简单的类似的接口,并根据webui.py的例子,加入ChatTTS模型功能,这边用的是webui中设定的默认语音种子2/42:
from flask import Flask, request, send_file
import torch
import numpy as np
import ChatTTS
import argparse
import torch._dynamo
torch._dynamo.config.suppress_errors = True
import io
from pydub import AudioSegment
app = Flask(__name__)
# 设置 Flask 应用的 IP 地址和端口
server_ip = '0.0.0.0' # 允许外部访问
server_port='8081' # 可以自定义端口
# 初始化ChatTTS模型的方法
def load_model():
parser = argparse.ArgumentParser(description='ChatTTS demo Launch')
parser.add_argument('--server_name', type=str, default='0.0.0.0', help='Server name')
parser.add_argument('--server_port', type=int, default=8081, help='Server port')
parser.add_argument('--local_path', type=str, default=None, help='the local_path if need')
args = parser.parse_args()
global server_ip
server_ip=args.server_name
global server_port
server_port=args.server_port
print("loading ChatTTS model...")
global chat
chat = ChatTTS.Chat()
if args.local_path == None:
chat.load_models()
else:
print('local model path:', args.local_path)
chat.load_models('local', local_path=args.local_path) # --local_path .\ChatTTS\model\chatTTS\
load_model()
@app.route('/v1/audio/speech', methods=['POST'])
def generate_speech():
data = request.get_json()
# model = data.get('model', 'tts-1')
input_text = data.get('input', '')
# voice = data.get('voice', 'alloy')
audio_seed_input=2
text_seed_input=42
torch.manual_seed(audio_seed_input)
rand_spk = chat.sample_random_speaker()
params_infer_code = {
'spk_emb': rand_spk,
'temperature': 0.3,
'top_P': 0.7,
'top_K': 20,
}
params_refine_text = {'prompt': '[oral_2][laugh_0][break_6]'}
torch.manual_seed(text_seed_input)
input_text = chat.infer(input_text,
skip_refine_text=False,
refine_text_only=True,
params_refine_text=params_refine_text,
params_infer_code=params_infer_code
)
# 使用ChatTTS模型生成音频
wav = chat.infer(input_text,
skip_refine_text=True,
params_refine_text=params_refine_text,
params_infer_code=params_infer_code
)
audio_data = np.array(wav[0]).flatten()
# 指定采样率
sample_rate = 24000
# 将音频数据转换为符合pydub要求的格式
audio_segment = AudioSegment(
data=(audio_data * 32767).astype(np.int16).tobytes(),
sample_width=2, # 16位
frame_rate=sample_rate,
channels=1 # 单声道
)
# 创建一个字节流,用于保存MP3文件
audio_io = io.BytesIO()
# 将AudioSegment对象转换为MP3格式,并写入字节流
audio_segment.export(audio_io, format="mp3")
# 查询音频数据
audio_io.seek(0)
# 创建响应对象,指定MIME类型和音频流
return send_file(audio_io, mimetype="audio/mp3")
if __name__ == '__main__':
app.run(debug=True, port=server_port)启动api:
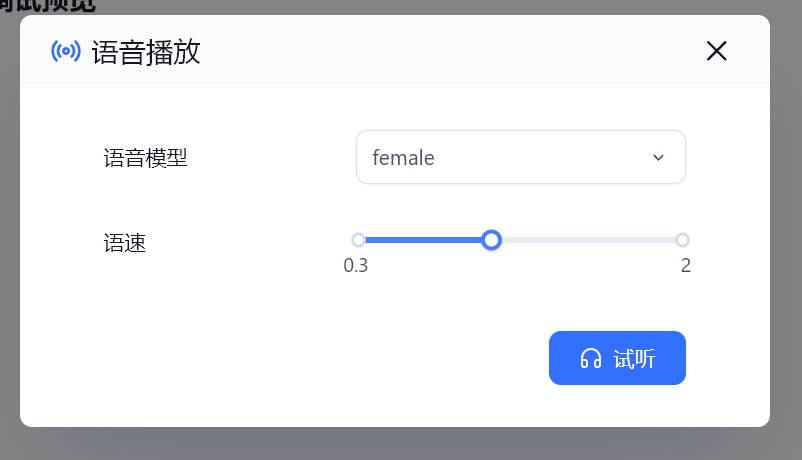
python .\open_api.py --local_path .\ChatTTS\model\chatTTS\测试正常,能够输出input中的文字语音:
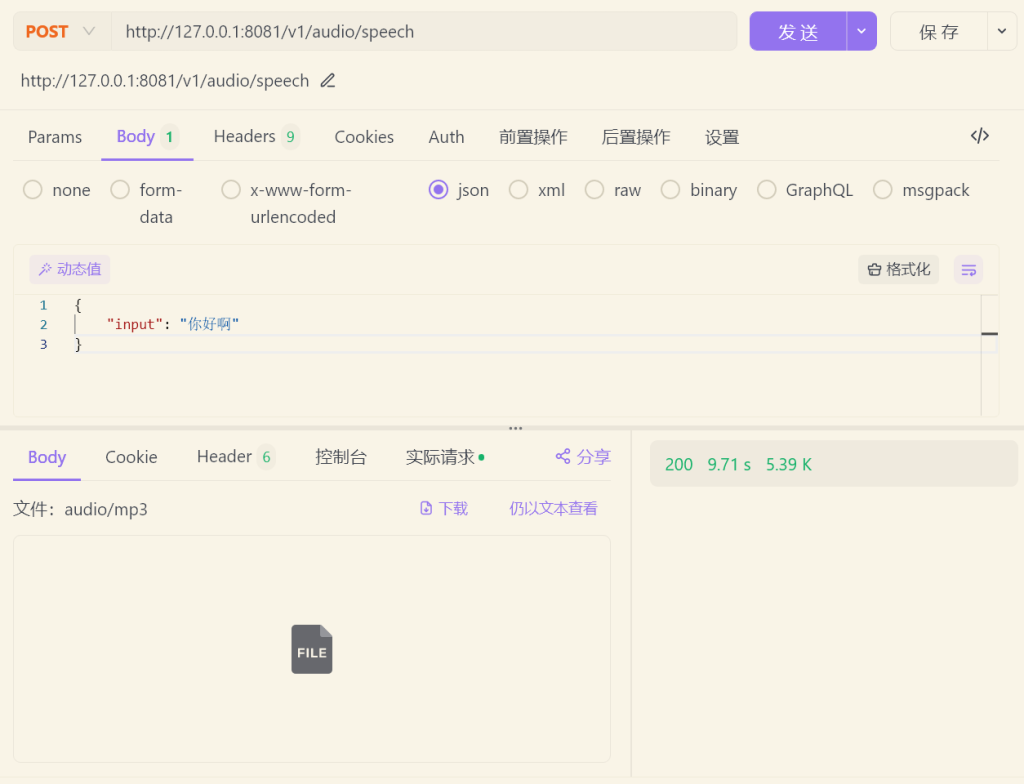
添加至FastGPT
编辑config.json
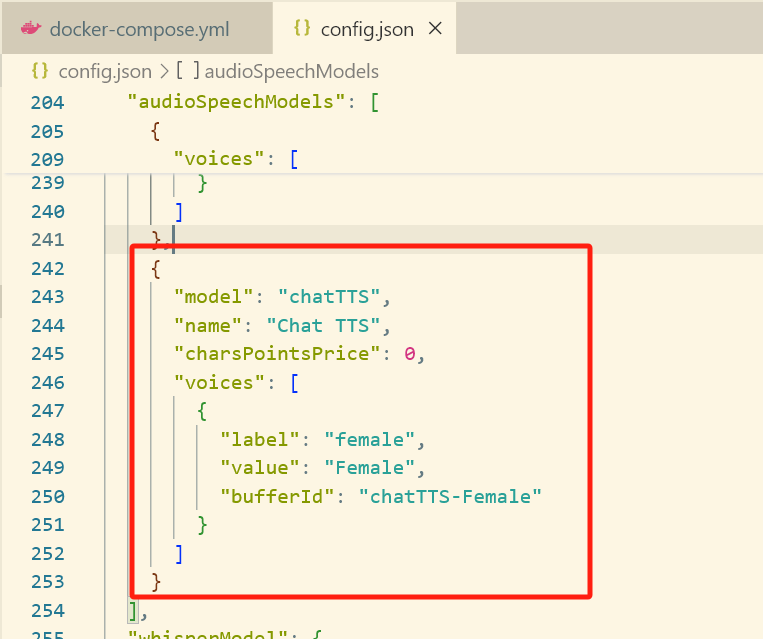
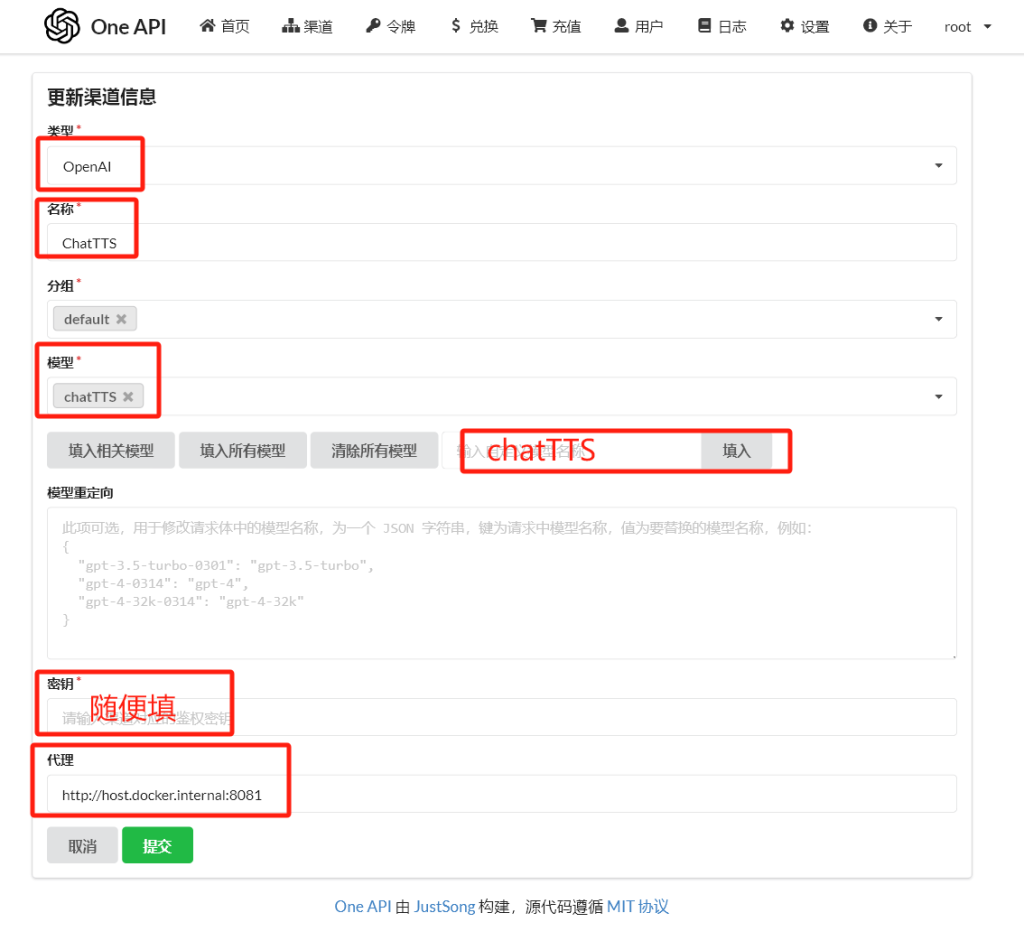
one-api中按下图填入模型
重启FastGPT和OneAPI容器,就可以体验啦